네이버 많이 본 TV연예 뉴스 1순위 가져오기
이번에는 약간 난이도를 높여서 네이버 TV연예 페이지에서 우측에 있는 많이 본 TV연예 뉴스를 가져와보자.

[초딩도 할 수 있는 파이썬] 네이버 금융에서 코스피 지수 가져오기에서 했던 방식 그대로 1순위 제목을 가져오려면 다음과 같이하면 된다.
[초딩도 할 수 있는 파이썬] 네이버 금융에서 코스피 지수 가져오기
네이버 금융에서 코스피 지수를 가져와보자. 위에서보면 네이버 금융 페이지 주소는 https://finance.naver.com/sise/sise_index.naver?code=KOSPI 임을 알 수 있고, 화면 중간에 2290.00이라는 오늘자 코스피 지..
pythontips.tistory.com
1. 웹페이지 주소는 https://entertain.naver.com/home이다.
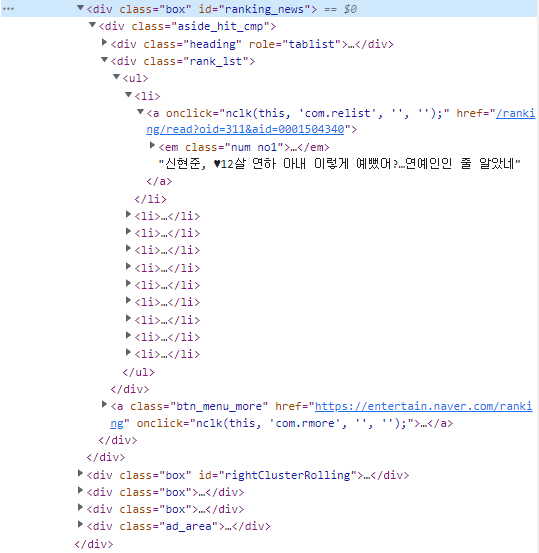
2. 1순위 기사 제목 위치의 selector 값은 #ranking_news > div > div.rank_lst > ul > li:nth-child(1) > a이다.
이를 참고하여 파싱 코드를 만들어보면 다음과 같다.
import requests
from bs4 import BeautifulSoup
naver_ent = requests.get("https://entertain.naver.com/home")
naver_ent_parser = BeautifulSoup(naver_ent.text, "html.parser")
naver_ent_1st = naver_ent_parser.select("#ranking_news > div > div.rank_lst > ul > li:nth-child(1) > a")
네이버 많이 본 TV연예 뉴스 10순위까지 모두 가져오기
유사하게 2순위 제목을 해보면 #ranking_news > div > div.rank_lst > ul > li:nth-child(2) > a 임을 알 수 있고, 쭉 찍어보면 nth-child(숫자)의 숫자가 변하면서 10순위는 #ranking_news > div > div.rank_lst > ul > li:nth-child(10) > a임을 알 수 있다. 이를 바탕으로 1순위부터 10순위까지 출력해보면 다음과 같다.

그런데 파싱을 하다보면 저렇게 예쁘게만 잘 골라지지 않고 selector를 직접 수정해야할 일들이 생긴다. 하여 이번 글에선 #ranking_news > div > div.rank_lst > ul > li:nth-child(1) > a의 의미를 파싱 목적으로만 필요한 것만 개략적으로 살펴보고자한다.
웹 스크래핑을 위한 웹페이지 구조 핵심 사항들
우리가보는 웹페이지는 HTML이라는 형식을 따르는데 모든 구조는 다음과 같다.
<태그명1 속성명1="속성값1">
<태그명2 속성명2="속성값2">
<태그명3 속성명3="속성값3"> 내용3 </태그명3>
<태그명4 속성명4="속성값4"> 내용4 </태그명4>
</태그명2>
</태그명1>
1. 속성명은 생략될 수 있다.
2. 태그명은 h1,h2, p, div, li, a 등이 올 수 있다.
3. 속성명에는 class, id 등이 올 수 있다. selector를 생성시 class는 .으로, id는 #으로 찾는다.
3. 태그명2는 태그명1의 자식이며, 태그명3, 태그명4는 태그명2의 자식, 태그명3, 태그명4는 태그명1의 자손이다. 자식을 찾을 때는 >로, 자손을 찾을 때는 (공백)으로 찾는다.
4. 태그명과 속성명이 똑같은 경우(예를들면, 태그명3=태그명4이고 속성명3=속성명4인 경우)엔 nth-child(숫자)로 몇번째에 있는지 표시한다.
네이버 많이 본 TV연예 뉴스 1순위 css selector 해석하기
이를 바탕으로 #ranking_news > div > div.rank_lst > ul > li:nth-child(1) > a을 해석해보면
1.id="ranking_news"인 태그의 div 자식 태그가 있고,
2. 다시 div class="rank_1st"인 자식 태그가 있고,
3. 다시 ul 자식 태그가 있고,
4. 다시 li 자식 태그의 첫번째를 찾고,
5. 그것의 a 자식 태그를 갖는 구조
를 의미한다. 그리고 위의 코드는 웹페이지 전체에서 이런 구조를 찾으면 우리가 원하는 1순위 기사 제목 위치가 나온다는 뜻이다.
css selector 변형하여 1순위부터 10순위까지 한꺼번에 가져오기
여기서 한가지 생각해보면 1순위부터 10순위까지의 정보는 ul의 자식 태그로 등장하고, a태그는 ul의 자손 태그이다. 따라서#ranking_news > div > div.rank_lst > ul a로 selector를 입력하면 모든 li 태그 정보들이 한꺼번에 반환될 것이다. 그럼 이렇게도 가능하다는 것을 알 수 있다.

'초딩도 할 수 있는 파이썬 자동화' 카테고리의 다른 글
| [초딩도 할 수 있는 파이썬] 티스토리 자동 로그인하기 (0) | 2022.09.29 |
|---|---|
| [초딩도 할 수 있는 파이썬] 강추 무료 학습 사이트 TOP 3 (2) | 2022.09.25 |
| [초딩도 할 수 있는 파이썬] 네이버 금융에서 코스피 지수 가져오기 (0) | 2022.09.23 |
| [초딩도 할 수 있는 파이썬] 네이버 웹페이지 가져오기 (0) | 2022.09.20 |
| 파이썬을 활용한 자동화 팁 정리 (0) | 2022.09.20 |