네이버 금융 사이트 html 긁어오기
네이버 금융에서 코스피 지수를 가져와보자.

위에서보면 네이버 금융 페이지 주소는 https://finance.naver.com/sise/sise_index.naver?code=KOSPI 임을 알 수 있고, 화면 중간에 2290.00이라는 오늘자 코스피 지수가 있음을 알 수 있다.
우선 네이버 금융 페이지를 reqeusts 모듈을 이용해 가져오고, BeautifulSoup을 이용해 파싱하기 좋은 객체로 만들자. 사이트 가져오는 방법은 다음 참조.
[초딩도 할 수 있는 파이썬] 네이버 웹페이지 가져오기
파이썬에서 특정 웹페이지 정보를 가져와서 분석하는 작업은 다음 두가지 단계로 이뤄진다. 순서 하는 일 모듈 1 웹페이지 정보를 가져온다. import requests 2 해당 웹페이지를 분석한다. from bs4 impor
pythontips.tistory.com
import requests
from bs4 import BeautifulSoup
naver_kospi = requests.get("https://finance.naver.com/sise/sise_index.naver?code=KOSPI")
naver_kospi_parser = BeautifulSoup(naver_kospi.text, "html.parser")
코스피 지수의 css selector 가져오는 방법
이제 naver_kospi_parser 객체에서 2290.00 숫자가 있는 부분만 골라내야한다. 저 부분을 찾아내기위한 과정은 다음과 같다.
1. 크롬 브라우저에서 F12를 눌러 우측에 웹페이지 소스 코드를 볼 수 있는 창을 띄운다. (위 이미지 우측 창 참조)
2. 우측 소스 코드 창 왼쪽 위 화살표 버튼을 누르고

3. 파싱하기 원하는 부분 위에 마우스 커서를 올려놓는다. 이 때 우측 소스 코드 창에 발견된 위치를 찾는게 중요.
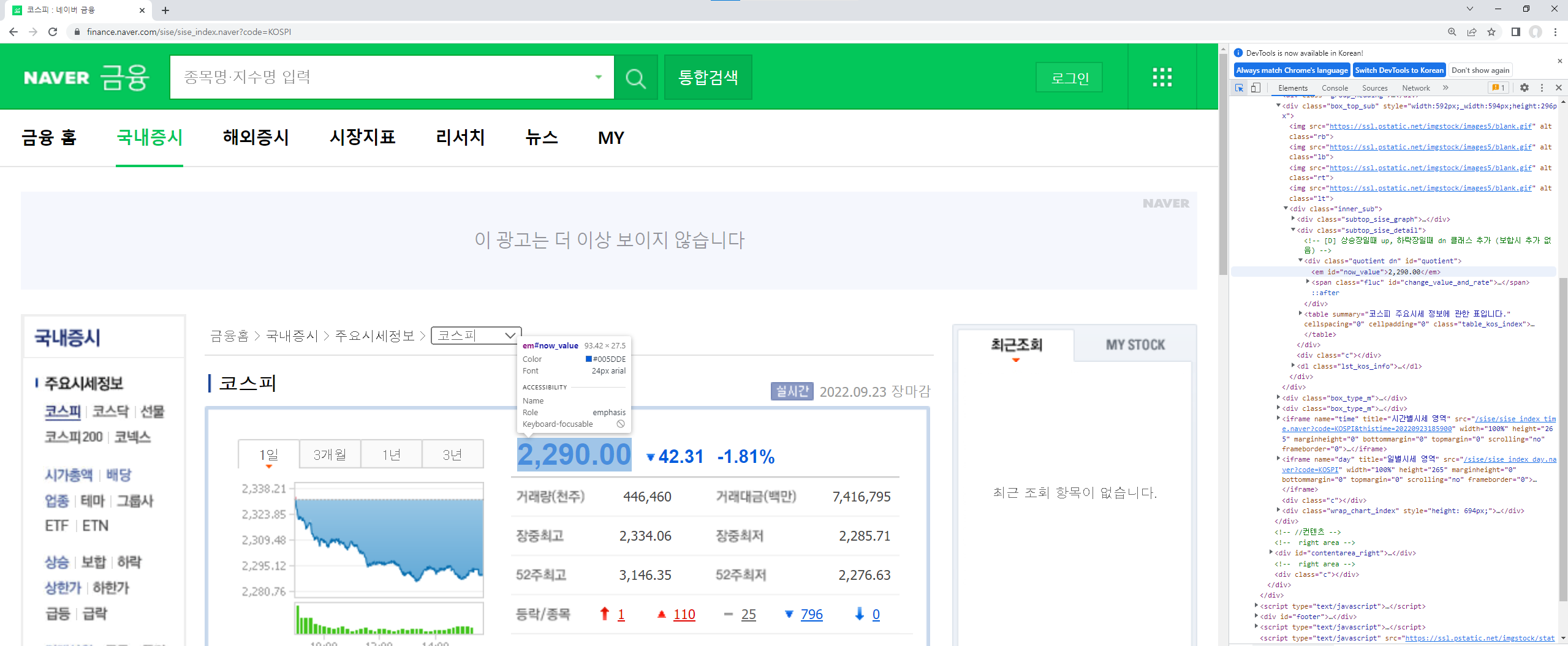
4. 소스 코드 창에서 발견된 위치로 가서 마우스 우클릭 -> copy -> copy selector 를 누른다.
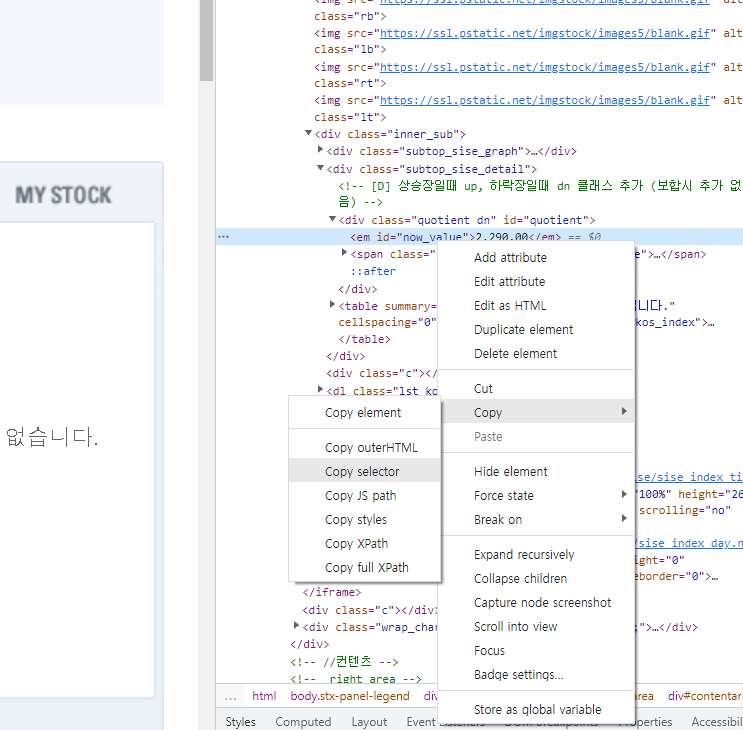
5. 이를 select 메서드에 넣는다. (이 경우엔 #now_value 가 복사되었다.)
kospi_now = naver_kospi_parser.select("#now_value")
출력해보면 다음과 같이 나온다.

select 메서드는 결과를 모두 찾아서 list 형식으로 반환하는데, 지금 같은 경우는 하나만 발견된 것을 알 수 있다.
따라서 위의 결과의 0번째 인덱스 값을 가져오고, 가운데 2290.00 값만 가져오고 싶다면 .text를 붙이면 된다.

사이트 html 파일을 가져와 원하는 부분을 찾는 일반적인 방법
정리하면 다음과 같다.
import requests
from bs4 import BeautifulSoup
naver_kospi = requests.get(**url**)
naver_kospi_parser = BeautifulSoup(naver_kospi.text, "html.parser")
kospi_now = naver_kospi_parser.select(**selector**)
1. 위 **url**에 파싱을 원하는 페이지 주소를 입력한다.
2. **selector**에 소스코드로부터 복사한 값을 넣는다.
3. 그렇게해서 반환된 list에서 원하는 값을 찾는다.
물론 해보면 모든 사이트가 이렇게 심플하게 작동하진 않는다.
복사한 selector를 좀 수정해야할 경우도 있고, 애초에 위와같은 방식으로 파싱하기 어려운 사이트들도 있다.
하지만 쉬운 경우부터 차근차근 하다보면 점점 요령도 생기고 익숙해지리라 생각한다.
'초딩도 할 수 있는 파이썬 자동화' 카테고리의 다른 글
| [초딩도 할 수 있는 파이썬] 티스토리 자동 로그인하기 (0) | 2022.09.29 |
|---|---|
| [초딩도 할 수 있는 파이썬] 강추 무료 학습 사이트 TOP 3 (2) | 2022.09.25 |
| [초딩도 할 수 있는 파이썬] 네이버 많이 본 TV연예 뉴스 가져오기 (0) | 2022.09.23 |
| [초딩도 할 수 있는 파이썬] 네이버 웹페이지 가져오기 (0) | 2022.09.20 |
| 파이썬을 활용한 자동화 팁 정리 (0) | 2022.09.20 |